首先很高興看到原PO發問
能夠這樣追逐更深入的技術,先恭喜你,離高手又更近一步了
我寫程式要飯也好一陣子了,分享一下我從聽說大流量很屌,想玩大流量,
到現在可以真正碰觸到大流量一路的心得
在開始之前,先回應原PO的 搶票網站 例子
https://imgur.com/TON1Nid

以這張圖架構圖,我只能看出
1. request 分流
2. 靜態資料緩存
這兩個很直觀的是可以解決一些問題,但這張圖似乎少了什麼東西?
以關鍵字餵狗 看到這張圖
https://i.imgur.com/LMzKBpw.png

(from: https://aws.amazon.com/tw/solutions/case-studies/tixcraft/)
)
從這個架構圖,我們可以再看出幾點
(這裡我只有單看架構圖,不看其他資訊)
1. 靜態 UI 有cache (最底下的 S3
2. 不管是 UI API (Tixcraft UI) 或是 public API(右邊的API) 都有分流
3. public API(右邊的API) 有cache
4. tranditional server 只能透過 tixcraft 進入
5. tranditional server 往 payment 是單向
6. pament 資料同步到 DynamoDB 供API取用
一開始我看不懂那個 tranditional server 的用意
為何要多繞一圈,把資料跑出去外面再繞回來?
照理說 Tixcraft UI 如果直接對 payment,完全在aws裡面,應該可以更有效率
直到我看到這篇文章 https://www.ithome.com.tw/news/94531
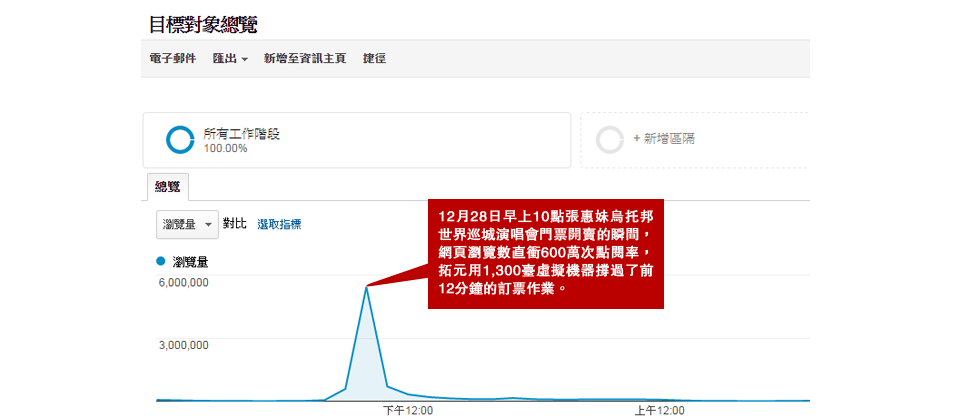
文章裡有一段是這麼寫的
“雖然邱光宗不願多透漏雲端購票系統的設計細節,不過,他表示,設計原則是採取多層
次架構,來解決資料庫連線數過高的問題”
看到這邊,我的理解是,他們是在不改變現有系統(tranditional server)的情況下,解
決突波性的流量的問題。我不確定他們實際上是怎麼做,但可以大膽猜測最後的結果是在 Tixcraft UI 裡面完成了類似 queue/cadidate picker 的行為,將先進(或是其他策
略)的用戶轉向原來就存在的系統。在現存的系統上進行付款,再將結果同步到 payment
和 dynamoDB 供查詢
突發流量問題以機器的數量去解決,提高了同時在線的容載量
但這只是高流量的特定一種場景,他們確實解決了突波性的流量
因為訂票性質的網站,買方的數量是固定的,且在一段時間內會持續被消耗
但如果今天場景是持續有這麼大量的request呢? 這系統會怎麼樣?
我想大概是在AWS 那一層被打爆(或是數量無限擴展)
直到 tranditional server 消耗速度可以跟上request數量
那麼 為什麼不把 tranditional server 直接放到 aws 上就好了?
我猜想是系統實作上沒有以可擴展的架構去設計和實作
所以在有限的資源內,他們當時只能針對request進來的路徑上先解決
而這確實解決了他們高流量的問題
那麼,如果他們當時是可擴展的架構
是不是把 tranditional server 直接放到 aws 上就好了呢?
我相信不是這麼簡單
訂票系統從直觀上看來,跳脫不了排隊、選座位、結帳這三件事(先不考慮複雜的情境)
排隊基本上不能平行處理
(Tixcraft解決的是讓大家可以同時在線的問題,而不是同時付款)
而 選座位和結帳 是可以的
就像電影院排隊,一定不會只有一個櫃檯在賣同一個廳的票
而選座位和結帳這個行為的平行化極限,取決於訂票流程(策略)的設計
該一次開放多少人來選票,這就是結帳平行度的極限
我想這個數量並不會大到必須要放到AWS去優化
所以拓元當時的解決方案是很合理且到位的
再來我們回到正題
我把你的問題拆解成以下2點
1. 怎麼取得相關知識
2. 怎麼活用在實戰
在說明這2點之前,請容我先給你一個反饋
原PO文裡說到的那些粗糙觀念,要把它磨到發亮
例如
“hash function因為返回的是index,所以在查找資料上非常快”
提問:
hash code 會不會重複? 重複了會發生什麼情形? 重複時,還能不能運作?
會怎麼運作? 回到根本, 什麼情況下要用 hash? 為什麼用?
“每次看到thread,大概就止步於看到那種for loop 交叉印出不同函數的例子”
提問:
能不能無限制的開thread? 極限在哪? 怎麼維護thread的數量?
thread的成本
是什麼? 怎麼降低成本? 怎麼維護input 與 thread數量之間的關係?
回到根本, 為什麼我的系統內要multi-thread? single-thread不行嗎?
(redis/nodejs告訴我們,可以)
這些問題的答案都是高流量的基礎
所以 yfr大大會說要一步步來,是有原因的
看到網路那些簡單的範例,要先問這個技術存在的原因是什麼?
它要解決什麼問題? 為什麼要這樣解決?
這些問題,在你之後面試時也會頻繁被問到
這並不是大家刻意在洗臉,而是真的有影響的
如果你發現面試被刻意考這些,但是進到裡面都沒有看到這些應用
那我真心認為你可以走了,再找其他家
1. 怎麼取得相關知識
怎麼取得,又分兩個問題: 知識、途徑
- 知識
網路上一大堆,但是我想你真正想問的是,我該下什麼關鍵字?
drajan 大大已經給出很多連結,可以從那裡去找
或許你會問,這麼多文章,我要從哪裡開始看? 這些技術我都用不到,真的有辦法活用
嗎?
我的建議是,真的不知道看什麼,就聽別人怎麼說
在 drajan 大大分享的
https://github.com/binhnguyennus/awesome-scalability#talk
這裡面有許多實戰的talk,這些都是知名企業真正碰到的問題和解法
每一個talk一定會說到他們碰到什麼問題,為什麼要用這個解法
你看多了,自然就會開始回頭去看各種基礎原理
我另外推薦一個較輕鬆的方法
就是在 youtube 上找 youtuber
這裡不是指程人頻道那種輕鬆的 talk
而是要找更 hardcore 的,會解說原理的
而且必須是你覺得夠輕鬆,願意且看得下去的
youtuber 這麼多,看到睡著代表不適合你
可能你程度不到看不懂,可能是說的不好,先換一個吧
例如我會看這位
https://www.youtube.com/watch?v=0vFgKr5bjWI
這個yt有許多篇已經改成付費會員才可看,如果你看過幾篇覺得順眼
強烈建議可以買訂閱,會有幫助的
另外像我是開發java ,用的是spring
所以我也會訂閱 spring framework 的頻道
這個方法可以試看看
- 途徑
你可以看到許多鄉民們一直提到 需求/場景/主題
這是因為高流量這件事在不同系統上的難處都不同
發生在哪裡(前端? API? consumer? DB?),以什麼樣的方式發生?
不會完全一樣
所以沒有一個萬用的架構,且牽扯到的觀念太繁太雜了
絕對沒有人可以跳出來跟你說該怎麼做
你也絕對不要期待在工作上遇到有前輩會跟你說
一來是因為他們的這些觀念都已經內化,對他們來說是基礎常識,不覺得要特別說,頂多
是在code review時會說要注意的地方
二來是畫著架構圖時候的那個房間,沒這些功力的人是進不去的
我自己看到白板上劃架構的時候,都是發生在面試時我畫給面試官看
所以你會發現一個事實
https://i.imgur.com/YLyjKel.jpg

開出高流量職缺的公司,通常都期待這個人會這些,最好也經歷過這些
所以沒這些經驗的人,到底該怎麼辦?
答案就是:就像 yfr大大說的,打好基礎知識,看talk學相關的觀念
在面試時,表示給面試官說,這些我都知道,我就是欠一個場景給我練練手!
千萬不要說,我會學。面試官只會OS: 你現在早該學會了
以我自己的經驗,我在沒有場景的公司,有想過這樣分散式的場景,該怎麼做
但實際上我並沒有去實現,只是把他畫出來,設想一遍
畫得出架構,並且說得出來這麼做的原因
也在之後的公司裡面驗證我的概念是正確的,因為我看到類似這樣的場景
所以自己去學那些觀念,並且假想場景並且設計是非常重要的
在高流量開發的當下,最重要的就是要有這些觀念存在心中
在我的想法裡,如果你的公司現在就沒有這種場景
你也不用花時間精力去提要做什麼高流量
一來是,可能沒這個需求,會被當成麻煩人物
二來是你做錯了,也沒有人有能力指導你
一間公司的高度通常在你進去的時候就決定了
除非你持續看到進到公司的人一個比一個還要強
否則,我認為就是投身到真正有這種場景的公司
所以在我看來,最大的重點就是想辦法找到這樣的公司
通常有些搞不清楚狀況(或是故意找碴)的面試官/獵頭會問你
那你們公司沒有高流量的架構嗎? 為什麼你自己不做高流量的架構?
我會這樣回答: 沒有場景,沒有必要 / 我做了其人會看不懂,沒能力維護
但是此時,如果又被追問,那麼如果是怎樣的場景,你怎麼做
這時候,你必須要有能力可以分析問題,說出你的看法
就像我前面分析搶票網站的過程(一定會被追問更多細節)
2. 怎麼活用在實戰
所有的高流量,都不會跳脫一個觀念,就是:快
所以在任何你讓一個request處理過程變快的改良,都是一個活用的迷你場景
就以你問的問題 “getallemployee” API 反問你
如果現在場景是 monolithic 的情況下,你怎麼讓這個API更快?
這個問題可以有不同假設,所以有不同的架構
改良可以做在DB上,資料結構上
會這麼問的原因是,在你看到的大型系統架構
有大部分是單機上碰到的問題的放大版
從 monolithic 到 distributed 的過程會有很多問題
例如當 employee 資料更新了,你怎麼確保資料的一致性?
在 distributed 的場景,drajan大大已經解答了(認同+1),如果你注意看的話,他說的
只是其中之一的解決方案
且他提到的 cache cluster ,硬要說的話,理論上也存在一致性的問題
(即便是時間非常短,或是沒有這問題,看cache cluster實作或配置而定)
那麼進一步,我們現在不看這個答案,
你能不能想出什麼方法可以實現在 distributed 場景上?
之所以不要在網路上找到其他方案,是因為你加入這樣的公司
勢必要有能力面對一個場景,這場景可能是你網路上找不到的問題
你的前輩或主管會預期你有辦法處理這種場景
我有看到 kvjo大大說到,通常大流量會有人負責做
不是資深的不會讓你碰
我認同這個看法,但認同一半
大流量的基礎架構確實讓有經驗的人去處理是最好的,
但是在架構出來之後,通常會伴隨產出一套專用的framework,
在這個framework之下,即使沒有經驗,但有概念的人也能夠知道是怎麼回事
在這些基礎下,可以更容易的學習到更多相關的經驗
而在這樣的基礎下,你開發的東西就已經是分散式的架構
你開發的東西,就必須符合高流量的水準
開發的過程中,去注意多執行緒和重複消費已經是基本
所以加入一家有高流量場景的公司,是最重要的
--
這篇寫得有點長,你有耐心看完,我會很感激XD
有什麼地方說不對,也歡迎指教
另外,我一直在想,這樣的經驗交流,我還沒有看到在哪裡有像discord這樣的群
可以找到人可以一起討論?
有沒有知道的大大有這種群可以加,大家一起勉勵
--
