IEEE:GPU很好,但不是唯一
https://www.qbitai.com/2024/03/131950.html

十三
CPU價值重新被發現
是時候讓CPU在AI應用上「支棱」起來了。
這是去年大語言模型大火之時,權威期刊 IEEE Spectrum 在一篇文章中,開門見山給出
的一個觀點;並且是由一群AI研究人員得出、聲量越來越大的那種。
文章還坦言道:
誠然GPU可能佔據了主導地位,但在AI領域中的許多情況下,CPU卻是更合適的那一個
。
例如文章引援了Hugging Face首席佈道官Julien Simon體驗的真實案例——
拿一個 英特爾® 至強® 系列CPU ,就能輕鬆駕馭Q8-Chat這個大語言模型,而且反應速
度很快。
Simon對此開誠佈公地表示:
GPU雖然很好,但壟斷從來不是一件好事,可能會加劇供應鏈問題並導致成本上升。
英特爾CPU在許多推理場景中都能很好地運作。
而這也正與當下大模型的發展趨勢變化相契合,即逐漸從訓練向推理傾斜,大模型不再僅
較真於參數規模、跑分和測評,更注重在應用側發力。
一言蔽之,比的就是看誰能 「快好省」 地用起來。
不過話雖如此,但在真實的AI場景中,CPU真的已經「支棱」起來了嗎?
京東雲,選擇CPU
如果說當時在這個話題上,IEEE扮演了“嘴替”,是在幫那些AI應用實踐的先行者們發聲
,那麼這種發聲,確實又吸引或帶動了更多實幹者來驗證這種可行性。 他們如今已經可
以給出一個確定答案,即在許多AI推理的場景中,CPU已經能很好地上崗了。
例如中國公有雲服務器市場的翹楚例如中國公有雲伺服器市場的翹楚京東 雲,它pick的
便是最新的 第五代英特爾® 至強® 可擴充處理器 。
具體而言,是在其新一代京東雲端伺服器上搭載了這款高階CPU。
話不多說,我們直接先來看效果。
首先,從整體來看,新一代京東雲端伺服器的整機效能最高提升了23%!
除此之外,在AI推理方面的表現也是Up Up Up。
電腦視覺推理:表現提升38%
Llama 2推理:性能提升51%
而之所以能有如此突破,核心就是第五代英特爾® 至強® 可擴展處理器內建的AMX(高
階矩陣擴充)技術對AI的加速能力。
英特爾® AMX 是針對矩陣運算推出的加速技術,支援在單一操作中計算更大的矩陣,讓
生成式AI 更快運作。
一言以蔽之,你可以把它當作內建在CPU中的Tensor Core。
展開來說, AMX引入了一種包含兩個組件的新矩陣處理框架,包括二維的寄存器文件,它
由被稱為“tile”的寄存器組成;另一個是一系列能夠在這些tile上執行操作的加速器。
在這些技術的加持之下,以向量檢索為例,當處理n個批次的任務時,需要對n個輸入向量
x和n個資料庫中的向量y進行相似度比較。
這一過程中的相似度計算涉及到大量的矩陣乘法運算,而英特爾® AMX能夠針對這類需求
提供顯著的加速效果。
https://tinyurl.com/bdzdkax9
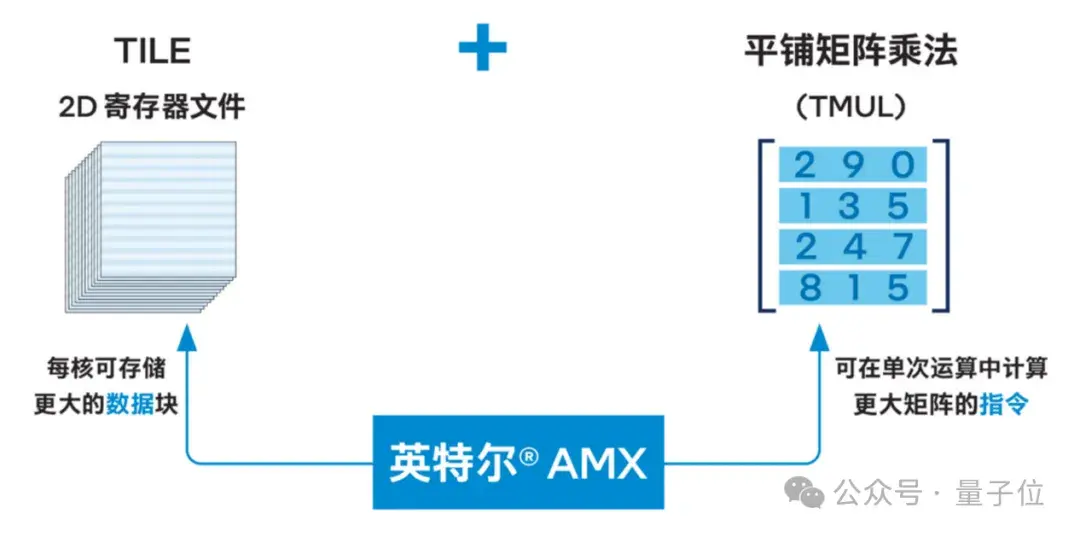
△英特爾® AMX架構
在提升模型效能的過程中, 英特爾® oneDNN 作為AMX的軟體搭檔,可為操作者提供一種
高效的最佳化實現方式。
開發者只需呼叫MatMul原語,並提供必要的參數,包括一些後處理步驟,oneDNN便會自動
處理包括配置塊寄存器、數據從內存的加載、執行矩陣乘法計算以及將結果回寫到內存等
一系列複雜操作,並在最後釋放相關資源。
這種簡化的編程模式顯著減輕了工程師的編程負擔,同時提升了開發效率。
透過上述軟硬結合的最佳化措施,京東雲端新一代伺服器就可以在大模型推理和傳統深度
學習模型推理等場景裡提供能滿足客戶效能和服務品質(QoS) 需求的解決方案,同時還可
以強化各種CPU本就擅長的通用運算任務的處理效率。 僅就大家關心的大模型推理而言,
已經能用於問答、客服和文件總結等多種場景。
https://tinyurl.com/45vjymn7
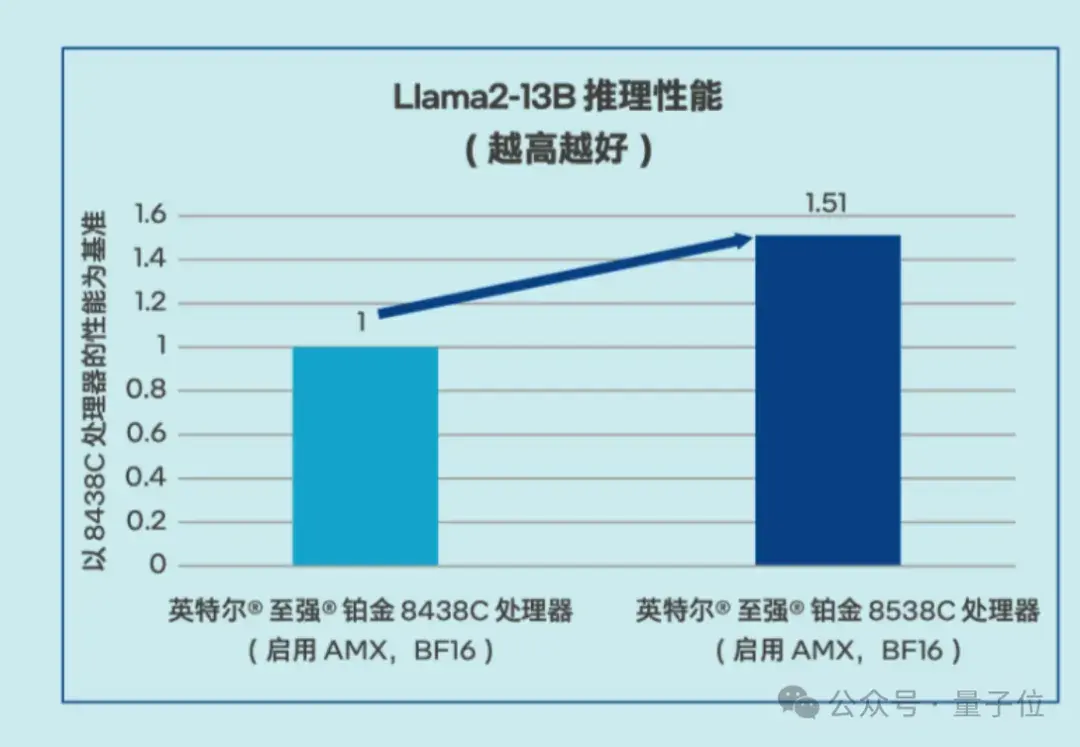
△Llama2-13B推理性能測試數據
而且除了效能上的最佳化之外,由於搭載了英特爾® AMX等模組,新一代京東雲端伺服器
也可以更快地回應中小規模參數模型,把成本也狠狠地打了下去。
你以為這就結束了? 英特爾CPU為新一代京東雲端伺服器帶來的好處,可不僅涉及推理加
速和成本,更可靠的安全防護也是其獨到優勢之一。
基於新款處理器內建的 英特爾® Trust Domain Extension (Intel® TDX)技術,京東
雲在不改變現有應用程式的情況下,就能建構基於硬體設備的可信任執行環境(Trusted
Execution Environment,TEE)。
英特爾® TDX透過引入 信任域 (Trust Domain,TD)虛擬環境,利用多密鑰全記憶體加
密技術,實現了不同TD、實例以及系統管理軟體之間的相互隔離,讓客戶的應用和資料與
外部環境隔離,防止未授權訪問,且效能損耗較低。
總的來說,英特爾CPU上的這項技術,是從硬體、虛擬化、記憶體到大模型應用等多個層
面,為新一代京東雲端伺服器的資料和應用保密提供了可靠支撐。
重新發現CPU的價值
AI進入2.0時代,所有應用都值得重寫一遍已逐漸成為共識。
如果站在算力基礎設施的視野重新檢視這場變革,還能發現這樣一個新趨勢:推理算力越
來越被重視起來。
也就是隨著大模型應用場景的日益豐富,對推理階段的效能要求也變得更高且多樣化。
一方面,即時性強、時延敏感的終端側場景需要盡可能短的反應時間;
另一方面,並發量大、吞吐量高的雲端服務則需要強大的批次能力。
同時,針對不同硬體平台、網路條件的推理適配也提出了更複雜甚至帶有不同前置條件的
要求。
如此一來,先前在硬體上的單一「審美觀」就被改寫,本來就主攻通用計算、能在整個AI
的協同編排中扮演重要角色,又能擼袖子自己上、兼顧AI加速,同時還有更多「才藝」、
應用適配也更為靈活,相比GPU或專用加速晶片獲取更容易,且已部署到無處不在的CPU,
其價值也被重新發現,這一切都順理成章。
相信隨著軟硬體適配的不斷深入,以及雲端端協同的加速落地,CPU還有望在AI,特別是
AI推理實踐中找到更多的用武之地,發揮更大的應用潛力。
可以預見,高性能、高效率、高適應性的CPU,在大模型越來越捲的時代,依舊是可靠的
選擇。 這一點,會有更多人因為實踐,而見證。
最後讓我們打個小廣告:為了科普CPU在AI推理新時代的玩法,量子位開設了 《最「in」
AI》 專欄,將從技術科普、產業案例、實戰優化等多個角度全面解讀。
我們希望透過這個專欄,讓更多的人了解CPU在AI推理加速,甚至是整個AI平台或全流程
加速上的實踐成果,重點就是如何更好地利用CPU來提升大模型應用的效能和效率。
--
